プロダクションで Swarm 利用時の考慮¶
この記事は Docker Swarm クラスタを計画・デプロイ・管理の手助けとなるガイダンスを提供します。想定しているのは、ビジネスにおけるクリティカルなプロダクション環境です。次のハイレベルな項目を扱います。
セキュリティ¶
Docker Swarm クラスタを安全にする様々な方法があります。このセクションは以下の内容を扱います。
TLS を使った認証
ネットワークのアクセス制御
これらのトピックだけでは完全ではありません。広範囲にわたるセキュリティ・アーキテクチャにおける一部分です。セキュリティ・アーキテクチャに含まれるのは、セキュリティ・パッチ、強力なパスワード・ポリシー、ロールをベースとしたアクセス制御、SELinux や AppArmor のように厳格な監査を行う技術、等々です。
Swarm 用の TLS 設定¶
Swarm クラスタ内にある全てのノードは、Docker Engine デーモンの通信用にポートを開く必要があります。そのため、中間者攻撃(man-in-the-middle attacks)のように、通常のネットワークに関連するセキュリティの問題をもたらします。対象のネットワークがインターネットのような信頼できない環境であれば、これらの危険性が倍増します。危険性を逓減するために、Swarm と Engine は TLS 認証(Transport Layer Security)をサポートしています。
Engine デーモンおよび Swarm マネージャは、TLS を使う設定をすることで、署名された Docker Engine クライアントからのみ通信を受け付けるようにできます。Engine と Swarm は組織内部の認証局(CA; Certificate Authorities)だけでなく、外部のサード・パーティー製による認証局もサポートしています。
Engine と Swarm が TLS に使うデフォルトのポート番号:
Engine デーモン:2376/tcp
Swarm マネージャ:3376/tcp
Swarm に TLS 設定を行うための詳しい情報は、 Swarm と TLS の概要 ページをご覧ください。
ネットワークのアクセス制御¶
プロダクションにおけるネットワークは複雑であり、通常は特定のトラフィックのみがネットワーク上に流れるように固定します。以下のリストは Swarm クラスタの各コンポーネントが公開しているポート情報です。ファイアウォールや、他のネットワーク・アクセス管理リストの設定に、これらが使えるでしょう。
Swarm マネージャ :
Inbound 80/tcp (HTTP):
docker pullコマンドが動作するために使います。Docker Hub からイメージを取得するためには、インターネット側のポート 80 を通す通信の許可が必要です。Inbound 2375/tcp :Docker Engine CLI が Engine デーモンと直接通信します。
Inbound 3375/tcp :Docker Engine CLI が Swarm マネージャと通信します。
Inbound 22/tcp :SSH を経由したリモート管理を行います。
サービス・ディスカバリ :
Inbound 80/tcp (HTTP) :
docker pullコマンドが動作するために使います。Docker Hub からイメージを取得するためには、インターネット側のポート 80 を通す通信の許可が必要です。Inbound (ディスカバリ・サービス用のポート番号) :バックエンド・ディスカバリ・サービス(consul、etcd、zookeeper)が公開するポートの設定が必要です。
Inbound 22/tcp :SSH を経由したリモート管理を行います。
Swarm ノード :
Inbound 80/tcp (HTTP) :
docker pullコマンドが動作するために使います。Docker Hub からイメージを取得するためには、インターネット側のポート 80 を通す通信の許可が必要です。Inbound 2375/tcp :Docker Engine CLI が Engine デーモンと直接通信します。
Inbound 22/tcp :SSH を経由したリモート管理を行います。
その他、ホスト横断コンテナ・ネットワーク :
Inbound 7946/tcp : 他のコンテナ・ネットワークから発見(ディスカバリ)されるために必要です。
Inbound 7946/udp : 他のコンテナ・ネットワークから発見(ディスカバリ)されるために必要です。
Inbound /tcp : キーバリュー・ストアのサービス用ポートに接続します。
7489/udp : コンテナのオーバレイ・ネットワーク用です。
もしもファイアウォールがネットワーク・デバイスとの接続状態を検出(state aware)すると、TCP 接続を確立するための応答を許可します。デバイスが検出できなければ、 23768 ~ 65525 までのエフェメラル・ポート(訳者注:短時間のみ利用するポート)を自分でオープンにする必要があります。エフェメラル・ポートのルールという、セキュリティ設定の追加のみが、既知の Swarm デバイス上のインターフェースからの接続を受け付けるようにします。
Swarm クラスタが TLS 用の設定を行っている場合、 2375 は 2376 に、 3375 は 3376 に置き換えます。
クラスタ作成やクラスタ管理、クラスタ上でコンテナをスケジューリングといった Swarm クラスタの操作には、先ほどのリストにあるポートの調整が必要です。アプリケーションに関連する通信のために、追加で通信用ポートの公開も必要になる場合があります。
Swarm クラスタのコンポーネントは、別のネットワークに接続する可能性があります。例えば、多くの組織が管理用のネットワークとプロダクション用のネットワークを分けています。ある Docker Engine クライアントは管理ネットワーク上に存在しており、 Swarm マネージャ、ディスカバリ・サービス用インスタンスやノードが1つまたは複数のネットワークにあるかもしれません。ネットワーク障害を埋め合わせるために、Swarm マネージャ、ディスカバリ・サービス、ノードが複数のプロダクション用ネットワークを横断することも可能です。先ほどのポート番号の一覧は、皆さんのネットワーク基盤チームがネットワークを効率的・安全に設定するために役立つでしょう。
高可用性(HA)¶
全てのプロダクション環境は高可用性(HA; Highly available )であるべきでしょう。つまり、長期間にわたる継続的な運用を意味します。高可用性を実現するのは、個々のコンポーネントで障害が発生しても切り抜ける環境です。
回復力のある高可用性 Swarm クラスタを構築するために、以下のセクションでは、いくつかの技術やベストプラクティスについて議論します。これらクラスタは、要求の厳しいプロダクションにおけるアプリケーションやワークロードで利用可能です。
Swarm マネージャ HA¶
Swarm マネージャは Swarm クラスタに対する全ての命令を受け付ける責任を持ちます。それと、クラスタ内のリソースをスケジューリングする役割があります。もしも Swarm マネージャが利用不可能になれば、再び Swarm マネージャが使えるようになるまでクラスタに対する操作が不可能になります。これは大きくスケールするビジネスにおいては致命的なシナリオであり、許されません。
Swarm が提供する HA 機能は、Swarm マネージャで発生しうる障害を緩和します。クラスタ上に複数の Swarm マネージャを設定することで、Swarm の HA 機能を利用できます。3つの Swarm マネージャがアクティブ/パッシブ(活動中/受け身)を形成します。この時、1つのマネージャが プライマリ であり、残りの全てが セカンダリ になります。
Swarm のセカンダリ・マネージャは ウォーム・スタンバイ として扱われます。つまり、プライマリ Swarm マネージャのバックグラウンドで動作することを意味します。セカンダリ Swarm マネージャはオンラインのままであり、プライマリ Swarm マネージャと同様、クラスタに対するコマンドを受け付けます。しかしながら、セカンダリが受信したコマンドはプライマリに転送され、その後に実行されます。プライマリ Swarm マネージャが落ちたとしても、残ったセカンダリの中から新しいプライマリが選出されます。
HA Swarm マネージャの作成時は、 障害範囲 (failure domains) の影響を受けないよう、可能な限り分散するよう注意を払う必要があります。障害範囲とは、デバイスまたはサービスに対する致命的な問題が発生すると影響があるネットワーク区分です。仮にクラスタが Amazon Web Services のアイルランド・リージョン(eu-west-1)で動いているとします。3つの Swarm マネージャを設定するにあたり(1つはプライマリ、2つはセカンダリ)、次の図のように各アベイラビリティ・ゾーンに置くべきでしょう。
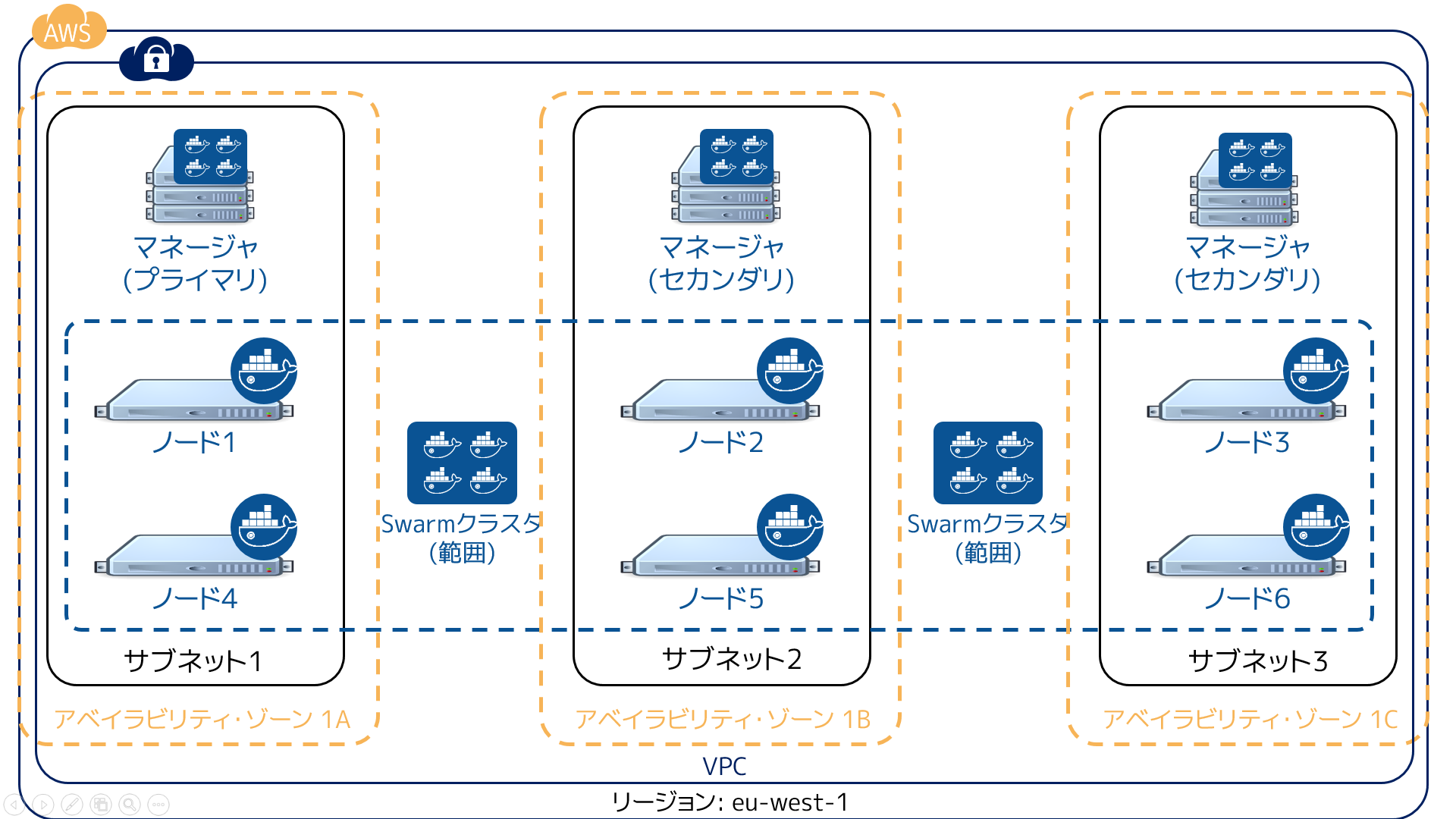
この設定であれば、Swarm クラスタは2つのアベイラビリティ・ゾーンが失われても稼働し続けられます。あなたのアプリケーションが障害を乗り越えるためには、アプリケーションの障害範囲も重複しないよう設計する必要があります。
事業部で需要の高いアプリケーション向けに Swarm クラスタを使う場合は、3つ以上の Swarm マネージャを準備すべきです。そのように設定しておけば、1つのマネージャがメンテナンスのために停止しても、あるいは障害に直面したとしても、クラスタを管理・運用し続けられます。
ディスカバリ・サービス HA¶
ディスカバリ・サービスは Swarm クラスタにおける重要なコンポーネントです。ディスカバリ・サービスが使えなくなると、適切なクラスタ操作ができなくなります。例えば、ディスカバリ・サービスが動作しなくなったら、クラスタに新しいノードの追加といった操作や、クラスタ設定に関する問い合わせに失敗します。これはビジネスにおけるクリティカルなプロダクション環境では許容できません。
Swarm は4つのバックエンド・ディスカバリ・サービスをサポートしています。
ホステッド(プロダクション向けではない)
Consul
etcd
Zookeeper
Consul 、 etcd 、 Zookeeper はどれもプロダクションにふさわしく、高可用性のために設定されるべきです。HA 向けのベスト・プラクティスを設定するためには、これら各サービスのツールを使うべきでしょう。
事業部で高い需要のアプリケーション向けに Swarm を使う場合は、5つ以上のディスカバリ・サービス・インスタンスの用意を推奨します。これはレプリケーション/HA で用いられている(Paxos や Raft のような)技術が強力なクォーラム(quorum)を必要とするためです。5つのインスタンスがあれば、1つがメンテナンスや予期しない障害に直面しても、強力なクォーラムを形成し続けられます。
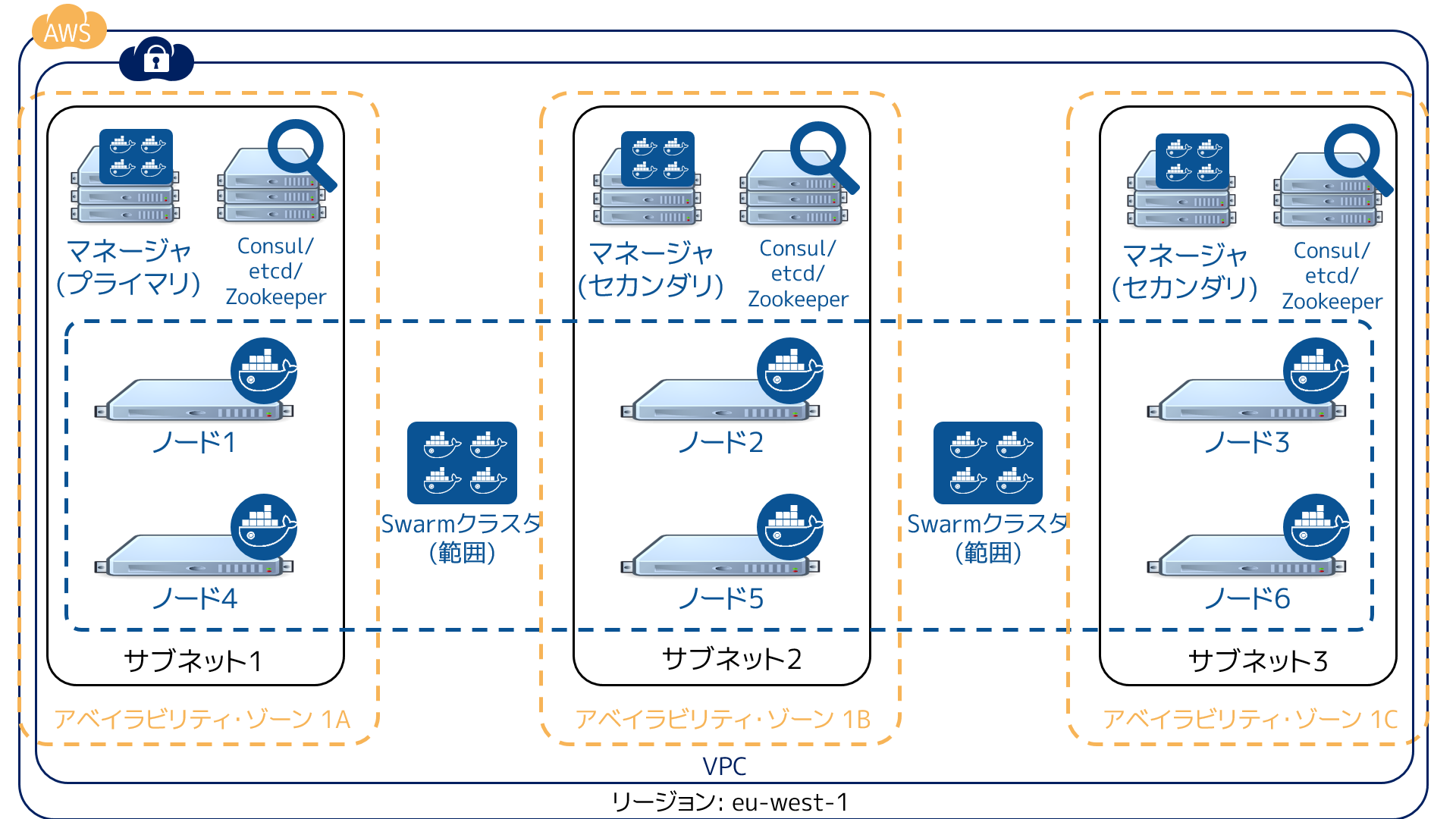
高い可用性を持つ Swarm ディスカバリ・サービスを作成する場合には、各ディスカバリ・サービス・インスタンスを可能な限り障害範囲を重複しないようにすべきでしょう。例えば、クラスタを Amazon Web Service のアイルランド・リージョン(eu-west-1)で動かしているとします。3つのディスカバリ・サービス用インスタンス設定する時、それぞれを各アベイラビリティ・ゾーンに置くべきです。
次の図は HA を設定した Swarm クラスタ設定を表しています。3つの Swarm マネージャと3つのディスカバリ・サービス・インスタンスが3つの障害領域(アベイラビリティ・ゾーン)に展開してます。また、 Swarm ノードは3つの障害領域を横断しています。2つのアベイラビリティ・ゾーンで障害が発生したとしても、Swarm クラスタは停止しない設定を表しています。
複数のクラウド¶
Swarm クラスタを複数のクラウド・プロバイダを横断するよう設計・構築できます。これはパブリック・クラウドでも、オンプレミスの基盤でもです。次の図は Swarm クラスタを AWS と Azure に横断しています。
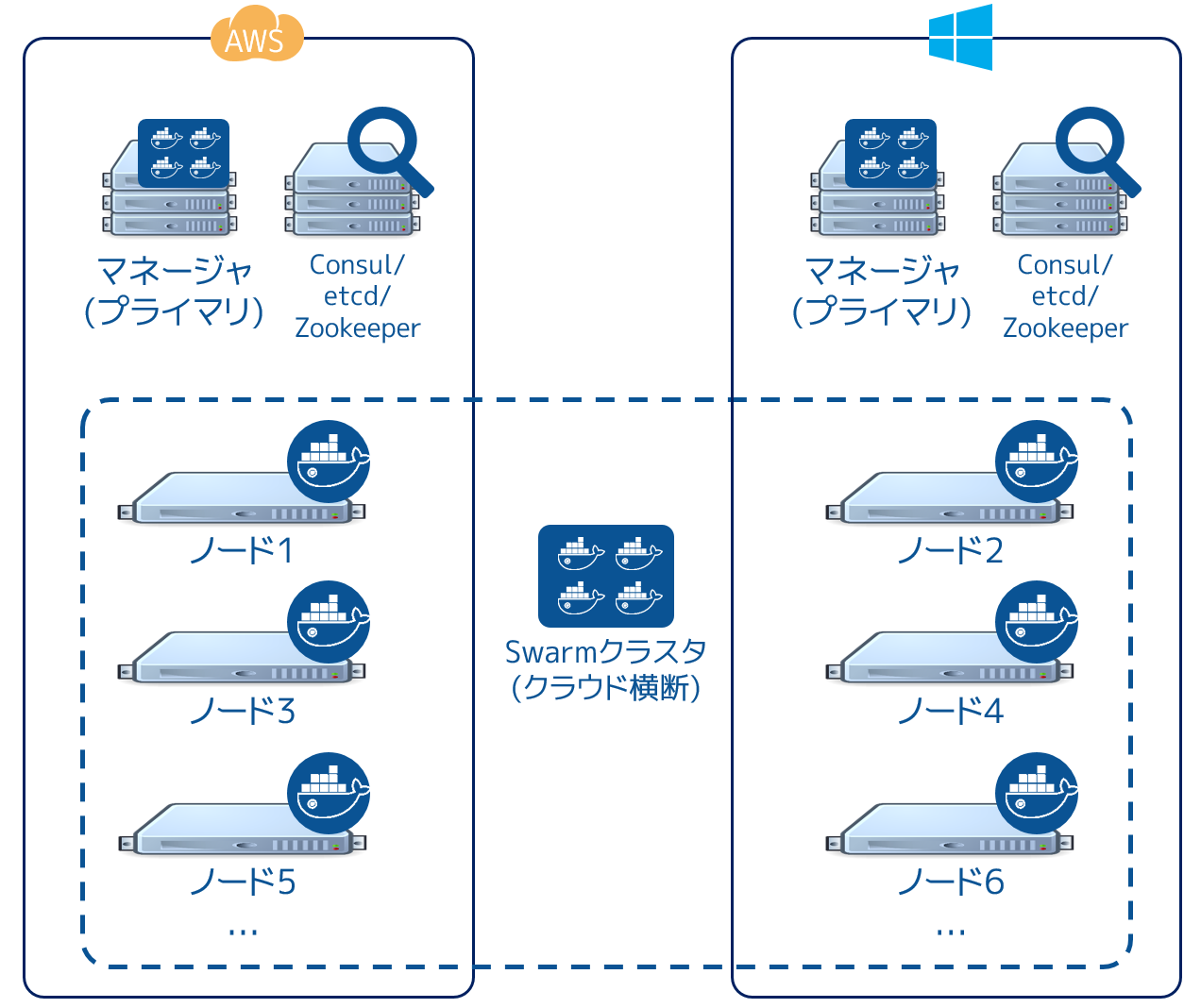
このアーキテクチャは究極の可用性を提供しているように見えるかもしれませんが、考慮すべき複数の要素があります。ネットワークのレイテンシ(応答遅延)は問題になりがちです。パーティショニング(分割)も問題になりうるでしょう。クラウド・プラットフォームにおいて信頼性、高スピード、低いレイテンシを実現する技術の考慮が必要となるでしょう。例えば AWS ダイレクト・コネクトや Azure ExpressRoute といった技術です。
このように、プロダクションを複数のインフラに横断する検討する場合は、あなたのシステム全体にわたるテストを確実に行うべきでしょう。
プロダクション環境の分離¶
開発、ステージング、プロダクションのような複数の環境を、1つの Swarm クラスタ上で動かせるでしょう。そのためには Swarm ノードをタグ付けし、 production や staging 等のようにタグ付けされたコンテナを制約フィルタ(constraint filter)で使う方法があります。しかしながら、これは推奨しません。ビジネスにおけるクリティカルなプロダクション環境において高いパフォーマンスが必要な時は、エアギャップ・プロダクション環境の手法を推奨します。
例えば、多くの会社では、プロダクション用に分離された専用環境にデプロイするでしょう。専用環境とは、ネットワーク、ストレージ、計算資源、その他のシステムです。デプロイは別の管理システムやポリシーで行われます。その結果、プロダクション・システム等にログインするために、別のアカウント情報を持つ必要があります。この種の環境では、プロダクション専用の Swarm クラスタへデプロイする義務があるでしょう。プロダクションのハードウェア基盤で Swarm クラスタを動かし、そこでプロダクションにおける管理・監視・監査・その他のポリシーに従うことになります。
オペレーティング・システムの選択¶
Swarm 基盤が依存するオペレーティング・システムの選択には重要な考慮をすべきです。考慮こそがプロダクション環境における核心となります。
開発環境とプロダクション環境でオペレーティング・システムを変えて使う会社は珍しくありません。よくあるのが、開発環境では CentOS を使いますが、プロダクション環境では Red Hat Enterprise Linux (RHEL) を使う場合です。しばしコストとサポートのバランスが決め手になります。CentOS Linux は自由にダウンロードして利用できますが、商用サポートのオプションは僅かなものです。一方の RHEL であればサポートに対してライセンスのコストが想定されますが、Red Hat による世界的な商用サポートが受けられます。
プロダクション向けの Swarm クラスタで使うオペレーティング・システムの選定にあたっては、開発環境とステージング環境で使っているものに近いものを選ぶべきでしょう。コンテナが根本となる OS を抽象化するといえども、避けられない課題があるためです。例えば、Docker コンテナのネットワークには Linux カーネル 3.16 以上が必要です。開発・ステージング環境でカーネル 4.x 系を使っているのに、プロダクションが 3.14 であれば何らかの問題が発生します。
他にも考慮すべき点として、手順、デプロイの順序、プロダクション用オペレーティング・システムへのパッチ適用の可能性があるでしょう。
性能¶
重要な商用アプリケーションを扱う環境にとって、性能(パフォーマンス)が非常に重要です。以下のセクションでは高性能な Swarm クラスタを構築する手助けとなるような議論と手法を紹介します。
コンテナ・ネットワーク¶
Docker Engine のコンテナ・ネットワークがオーバレイ・ネットワークであれば、複数の Engine ホスト上を横断して作成可能です。そのためには、コンテナ・ネットワークがキーバリュー(KV)・ストアを必要とします。これは Swarm クラスタのディスカバリ・サービスで情報を共有するために使います。しかしながら、最高の性能と障害の分離のためには、コンテナ・ネットワーク用と Swarm ディスカバリ用に別々の KV インスタンスをデプロイすべきでしょう。特に、ビジネスにおけるクリティカルなプロダクション環境においては重要です。
Engine のコンテナ・ネットワークは Linux カーネルの 3.16 以上を必要とします。より高いカーネル・バージョンの利用が望ましいのですが、新しいカーネルには不安定さというリスクが増えてしまいます。可能であれば、皆さんがプロダクション環境で既に利用しているカーネルのバージョンを使うべきです。もしも Linux カーネル 3.16 以上をプロダクションで使っていなければ、可能な限り早く使い始めるべきでしょう。
スケジューリング・ストラテジ¶
スケジューリング・ストラテジとは、 Swarm がコンテナを開始する時に、どのノードか、どのクラスタ上で実行するかを決めるものです。
spread
binpack
random (プロダクション向けではありません)
自分自身で書くこともできます。
spread (スプレッド)はデフォルトのストラテジです。クラスタ上の全てのノードにわたり、均一な数のコンテナになるようバランスを取ろうとします。高い性能を必要とするクラスタでは良い選択肢です。コンテナのワークロードをクラスタ全体のリソースに展開するからです。リソースには CPU 、メモリ、ストレジ、ネットワーク帯域が含まれます。
もし Swarm ノードで障害が発生したら、Swarm は障害領域を避けてコンテナを実行するようにバランスを取ります。しかしながら、コンテナの役割には注意が払われないため、関係なく展開されます。そのため、サービス展開先を複数の領域に分けたくても、Swarm は把握できません。このような操作を行うには、タグと制限(constraint)を使うべきです。
binpack (ビンバック)ストラテジは、ノードに次々とコンテナをスケジュールするのではなく、可能な限り1つのノード上にコンテナを詰め込もうとします。
つまり、binpack はクラスタを使い切るまで全てのクラスタ・リソースを使いません。そのため、binpack ストラテジの Swarm クラスタ上で動作するアプリケーションによっては、性能が出ないかもしれません。しかしながら、binpack は必要なインフラとコストの最小化のために良い選択肢です。例えば10ノードのクラスタがあり、それぞれ 16 CPU ・128 GB のメモリを持っていると想像してみましょう。コンテナのワークロードが必要になるのは、6 CPU と 64 GB のメモリとします。spread ストラテジであれば、クラスタ上の全てのノードにわたってバランスを取ります。一方、binpack ストラテジであれば、コンテナが1つのノード上を使い切ります。そのため、追加ノードを停止することで、コストの節約ができるかもしれません。
クラスタの所有¶
所有者が誰なのかというのは、プロダクション環境において極めて重要です。Swarm クラスタでプロダクションの計画、ドキュメントか、デプロイに至る全てにおける熟慮と合意が重要になります。
プロダクションの Swarm 基盤に対し、誰が予算を持っているのか?
プロダクションの Swarm クラスタを誰が管理・運用するのか?
プロダクションの Swarm 基盤に対する監視は誰の責任か?
プロダクションの Swarm 基盤のパッチあてやアップグレードは誰の責任か?
24 時間対応やエスカレーション手順は?
このリストは完全ではありません。何が答えなのかは、皆さんの組織やチーム構成によって様々に依存します。ある会社は DevOps の流れに従うかもしれませんし、そうではない場合もあるでしょう。重要なのは、皆さんの会社がどのような状況なのかです。プロダクション用 Swarm クラスタの計画、デプロイ、運用管理に至るまで、全ての要素の検討が重要です。
関連情報¶
参考
- Plan for Swarm in production