アプリケーションのトラブルシュート¶
何事も失敗するのが、人生における現実です。これを前提に、障害が発生したらどのように対処すべきか考えるのは重要です。以下のセクションでは、いくつかの障害シナリオを扱います。
- Swarm マネージャ障害
- Consul(ディスカバリ・バックエンド)障害
- Interlock ロードバランサ障害
- ウェブ(web-vote-app)障害
- Redis 障害
- ワーカ(vote-worker)障害
- Postgres 障害
- results-app 障害
- インフラ障害
Swarm マネージャ障害¶
現在の設定では、 Swarm クラスタには1つのホスト上で1つのマネージャ用コンテナしかありません。コンテナが終了したりノード障害が発生したりしますと、クラスタを管理できなくなるだけでなく、修復や入れ替えも不可能になります。
Swarm マネージャ・コンテナが予期せず終了して障害になった場合、Docker は自動的にコンテナの再起動を試みます。これはコンテナ起動時に --restart=unless-stopped に切り替える設定をしたからです。
Swarm マネージャが利用不可能になれば、アプリケーションは現状の設定で実行し続けます。しかし、Swarm マネージャが使えるようになるまで、ノードやコンテナをプロビジョンできなくなります。
Docker Swarm は Swarm マネージャの高可用性をサポートしています。そのため、1つのクラスタ上に2つ以上のマネージャを追加可能です。あるマネージャがプライマリ・マネージャとして選ばれたら、その他のものはセカンダリになります。プライマリ・マネージャで障害が発生したら、他のセカンダリから新しいプライマリ・マネージャが選び出され、クラスタの操作をし続けることが可能になります。高可用性に対応した Swarm マネージャを複数デプロイする場合は、インフラ上で複数の領域を横断する障害発生を考慮したほうが良いでしょう。
Consul(ディスカバリ・バックエンド)障害¶
この Swarm クラスタは、クラスタのディスカバリ・サービスとして、1つのノード上で Consul コンテナを1つデプロイしました。このセットアップ方法では、もし Consul コンテナを終了するかノード障害が発生しても、現在の状態のままアプリケーションを実行できるかもしれません。しかしながら、クラスタ管理に関する処理は障害になります。障害範囲は、クラスタ上に新しいコンテナの登録ができなくなり、クラスタに対して設定確認も行えません。
consul コンテナが予期せず終了して障害になった場合、Docker は自動的にコンテナの再起動を試みます。これはコンテナ起動時に --restart=unless-stopped に切り替える設定をしたからです。
consul 、 etcd 、 Zookeeper の各ディスカバリ・サービス・バックエンドは、様々な高可用性のオプションをサポートしています。これらには Paxos/Raft クォーラムが組み込まれています。高可用性に対応した設定をするには、あなたが選んだディスカバリ・サービス・バックエンドに対する既存のベスト・プラクティスを確認すべきです。高可用性のために複数のディスカバリ・サービス・バックエンドをデプロイするのであれば、インフラ上で複数の領域に横断した障害発生への対処を考えるべきです。
1つのディスカバリ・バックエンド・サービスで Swarm クラスタを操作する場合、このサービスが停止すると修復不可能になります。そのような場合は、新しいディスカバリ・バックエンド用のインスタンスを起動し直し、クラスタの各ノード上で Swarm エージェントを実行し直す必要があります。
障害の取り扱い¶
コンテナの障害には様々な理由が考えられます。しかしながら、Swarm はコンテナで障害が発生しても再起動を試みません。
コンテナの障害発生時、自動的に再起動する方法の1つは、コンテナ起動時に --restart=unless-stopped フラグを付けることです。これはローカルの Docker デーモンに対して、コンテナで不意な終了が発生した場合に再起動するよう命令します。これが正常に機能するのは、コンテナを実行するノードと Docker デーモンが正常に稼働し続ける状況のみです。コンテナを実行するホスト自身で障害が発生したら、コンテナを再起動できません。あるいは、Docker デーモン自身が障害となっているでしょう。
別の方法としては、外部のツール(クラスタ外にあるツール)を使ってアプリケーションの状態を監視し、適切なサービス・レベルを維持する方法があります。サービス・レベルとは「少なくともウェブサーバのコンテナを10動かす」といったものです。このシナリオでは、ウェブ・コンテナの実行数が10以下になれば、ツールが何らかの方法で足りない数だけコンテナの起動を試みます。
今回のサンプル投票アプリケーションでは、フロントエンドはロードバランサがあるためスケーラブル(スケール可能)です。2つのウェブ・コンテナで障害が発生すると(あるいは実行している AWS ホスト自身での障害が起これば)、ウェブ・コンテナに対するリクエストがあってもロードバランサは障害対象へのルーティングを停止し、別の経路に振り分けできます。ロードバランサの背後にn個のウェブ・コンテナを起動できるますのでで、この方法は高い拡張性を持つと言えるでしょう。
Interlock ロードバランサ障害¶
今回の例では、1つのノード上で1つの interlock ロードバランサを実行する環境を構築しました。このセットアップ方法では、コンテナが終了するかノード障害が発生したら、アプリケーションはサービスに対するリクエストを受け付けできなくなり、アプリケーションが利用不可能になります。
interlock コンテナが不意に終了すると障害になり、Docker は自動的に再起動を試みます。これはコンテナ起動時に --restart=unless-stopped フラグを付けたからです。
高可用性のある Interlock ロードバランサを構築可能です。複数のノード上に複数の Interlock コンテナを実行する方法があります。後は DNS ラウンドロビンの使用や、その他の技術により、Interlock コンテナに対するアクセスを負荷分散します。この方法であれば、1つの Interlock コンテナやノードがダウンしたとしても、他のサービスがリクエストを処理し続けます。
複数の Interlock ロードバランサをデプロイする場合は、インフラ上で複数の領域に横断した障害発生への対処を考えるべきです。
ウェブ(web-vote-app)障害¶
今回の環境では、2つのノードで2つのウェブ投票用コンテナを実行するように設定しました。これらは Interlock ロードバランサの背後にあるため、受信した接続は両者にまたがって分散されます。
もし1つのウェブコンテナもしくはノードで障害が発生しても、ロードバランサは生存しているコンテナに全てのトラフィックを流し続けますので、サービスは継続します。障害のあったインスタンスが復旧するか、あるいは追加した所に切り替えれば、受信したリクエストを適切に処理するようロードバランサの設定を変更します。
最も高い可用性を考えるのであれば、2つのフロントエンド・ウェブ・サービス( frontend01 と frontend02 )をインフラ上の異なった障害ゾーンへデプロイすることになるでしょう。あるいは、更なるデプロイの検討も良いかもしれません。
Redis 障害¶
redis コンテナで障害が発生したら、一緒に動作している web-vote-app コンテナも正常に機能しなくなります。一番良い方法は対象インスタンスの正常性を監視するよう設定し、各 Redis インスタンスに対して正常な書き込みができるかどうか確認することです。もし問題のある redis インスタンスが発見されれば、 web-vote-app と redis の連係を切り離し、復旧作業にあたるべきです。
ワーカ(vote-worker)障害¶
ワーカ・コンテナが終了するか、実行しているノードで障害が発生したら、redis コンテナは worker コンテナが復旧するまで投票キューを保持します。ワーカが復旧するまでその状態が維持され、投票も継続できます。
もし worker01 コンテナが不意に停止して障害になれば、Docker は自動的に再起動を試みます。これはコンテナ起動時に --restart=unless-stopped フラグを付けたからです。
Postgres 障害¶
今回のアプリケーションでは HA や Postgres のレプリケーションを実装していません。つまり Postgres コンテナの喪失とは、アプリケーションの障害だけでなく、データの損失または欠損を引き起こす可能性があります。何らかの Postgres HA やレプリケーションのような実装をすることが望ましい解決策です。
results-app 障害¶
results-app コンテナが終了したら、コンテナが復旧するまで結果をブラウザで表示できなくなります。それでも投票データを集めてカウントを継続できるため、復旧は純粋にコンテナを立ち上げるだけで済みます。
results-app コンテナは起動時に --restart=unless-stopped フラグを付けています。つまり Docker デーモンは自動的にコンテナの再起動を試みます。たとえそれが管理上の停止だったとしてもです。
インフラ障害¶
アプリケーションの障害は、その支えとなるインフラによって様々な要因があります。しかしながら、いくつかのベストプラクティスは移行の手助けや障害の緩和に役立つでしょう。
方法の1つは、可能な限り多くの障害領域にインフラのコンポーネントを分けてデプロイします。AWS のようなサービスでは、しばしインフラの分散や、複数のリージョン AWS アベイラビリティ・ゾーン(AZ)を横断することです。
Swarm クラスタのアベイラビリティ・ゾーンを増やすには:
- HA 用の Swarm マネージャを、異なった AZ にある HAノードにデプロイ
- HA 用の Consul ディスカバリ・サービスを、異なった AZ にある HA ノードにデプロイ
- 全てのスケーラブルなアプリケーションのコンポーネントを、複数の AZ に横断させる
この設定を反映したものが、次の図です。
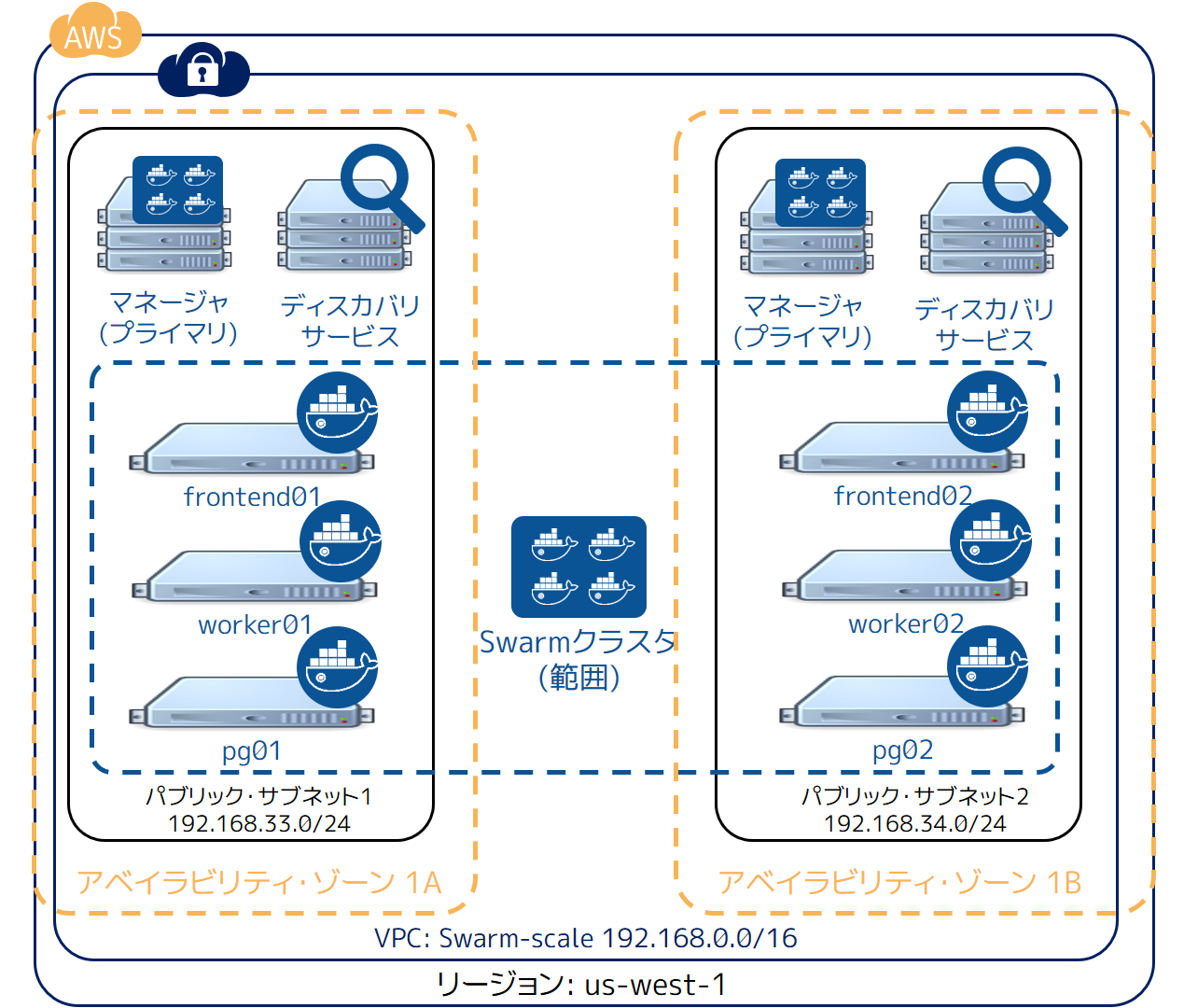
この手法であれば AZ 全体を喪失しても、クラスタとアプリケーションを処理可能です。
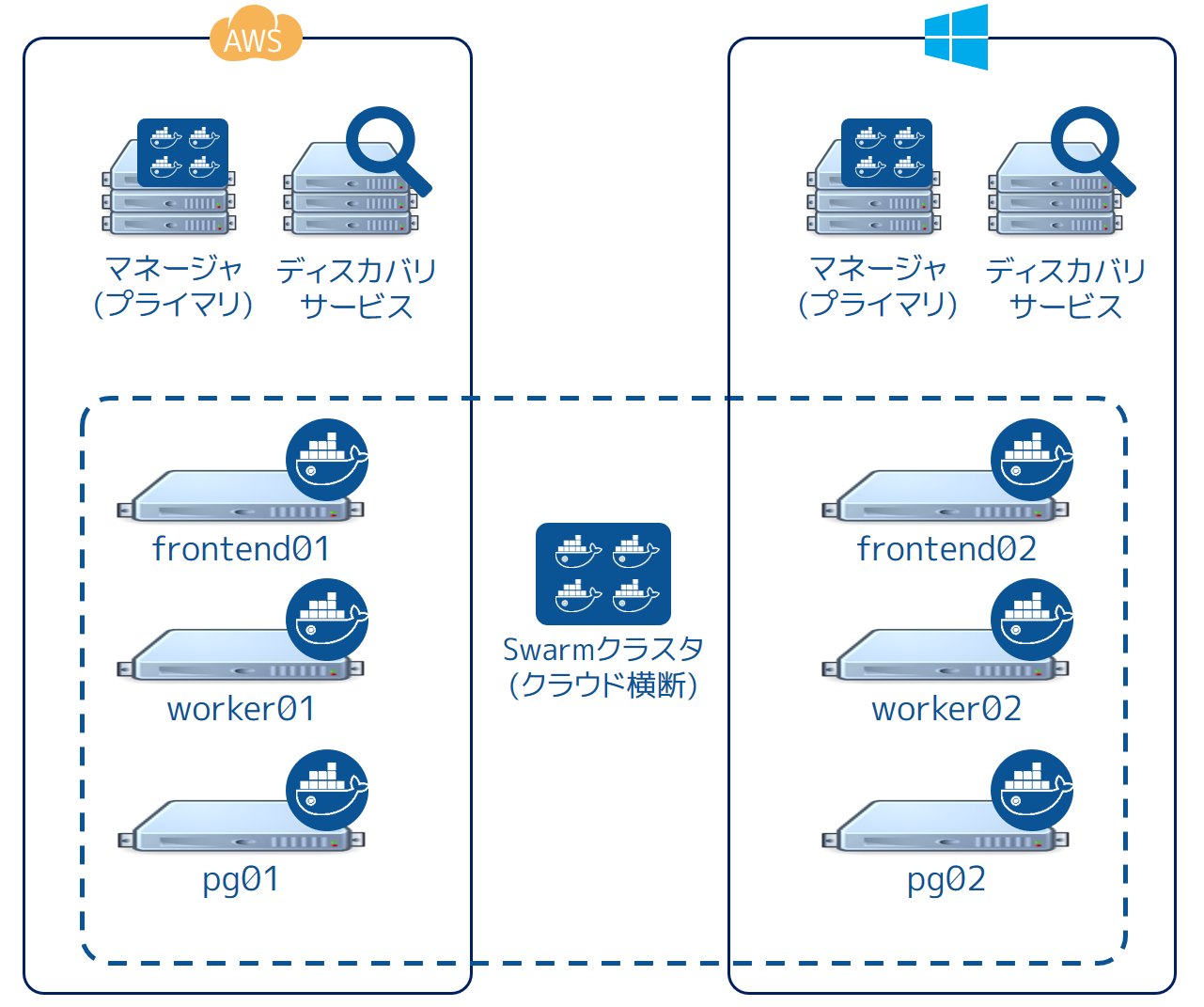
しかし全く止まらない訳ではありません。アプリケーションによっては AWS リージョンを横断して分散されているかもしれません。私たちのサンプルでは、クラスタとアプリケーションを us-west-1 リージョンにデプロイし、データを us-east-1 に置いています。この状態から、更にクラウド・プロバイダを横断するデプロイや、あるいはパブリック・クラウド・プロバイダや自分のデータセンタにあるオンプレミスに対して分散することもできるでしょう!
以下の図はアプリケーションとインフラを AWS と Microsoft Azure にデプロイしたものです。ですが、クラウドプロバイダはデータセンタにあるオンプレミスに置き換えても構いません。これらのシナリオでは、ネットワークのレイテンシと信頼性がスムーズに動作させるための鍵となります。
関連情報¶
このサンプル・アプリケーションは Docker Universal Control Plane (UCP) にもデプロイできます。UCP を皆さんの環境で試したい場合は、 UCP へのアクセス・リクエスト のページをご覧ください。
参考
- Troubleshoot the application
- https://docs.docker.com/swarm/swarm_at_scale/05-troubleshoot/